8月初,《自然》(Nature)杂志上线了由深度学习三巨头之一 Yoshua Bengio 领衔,MIT、剑桥、康奈尔、微软、英伟达等大咖云集的综述文章《Scientific discovery in the age of artificial intelligence》,以前瞻视角探讨人工智能时代的科学发现。百奥几何创始人唐建博士是作者之一。
这篇论文回顾了过去十年 AI 技术的关键突破,包括自监督学习(使模型能够在大量未标记数据上进行训练)、几何深度学习(利用对科学数据的几何结构提高模型的准确性和效率)、生成式 AI 方法(运用 AI 生成新的数据,例如小分子药物和蛋白质),讨论了这些技术如何在科学发现过程中帮助科学家,并指出各个科学领域的科学家应当合作发展基础性算法,促使 AI 帮助人们发现或自主发现科学知识。
AI for Science
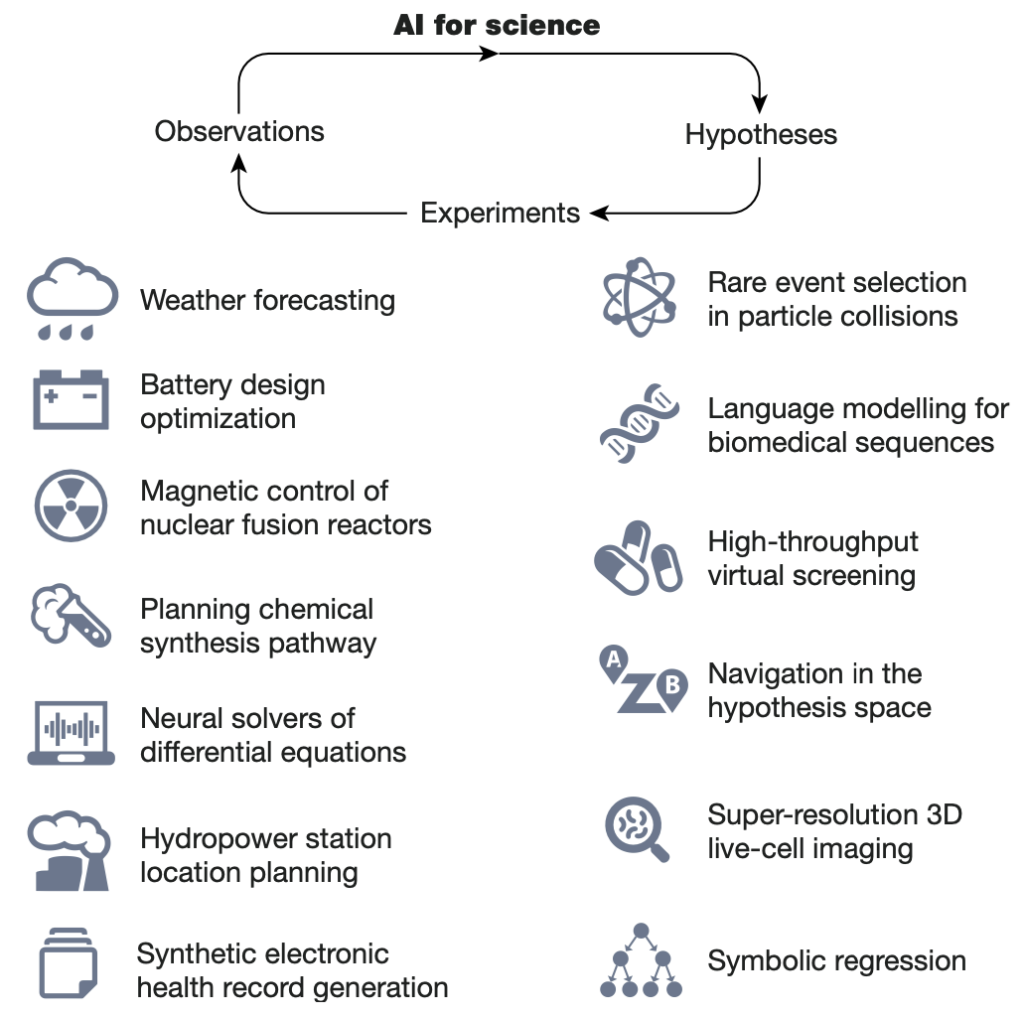
AI 正在重塑科学发现,增强和加速假说生成、实验设计、数据收集、数据分析等各个研究环节(如上图)。与 AI 赋能的其他领域相比,将 AI 用于科学创新和发现(AI4Science)存在独特的挑战。其一,科学问题中浩瀚的假设空间使得系统性的探索和遍历不可行。例如,在生物化学领域约有 10^60 种潜在的药物分子有待评估。其二,训练接近实验精度的 AI 模型需要可靠的标注数据集,但数据标注依赖耗时费力的实验和仿真。
尽管存在这些挑战,AI4Science 已经取得了长足进展,比如成功突破长达 50 年的蛋白质折叠问题和对百万级粒子构成的分子系统的模拟。这些案例都展示了 AI 解决复杂科学问题的卓越能力。当然,与任何新技术一样,AI4Science 的最终成功取决于我们能否将其深度融入日常科学实践,以及能否准确把握其潜力和局限。
用 AI 学习数据表征
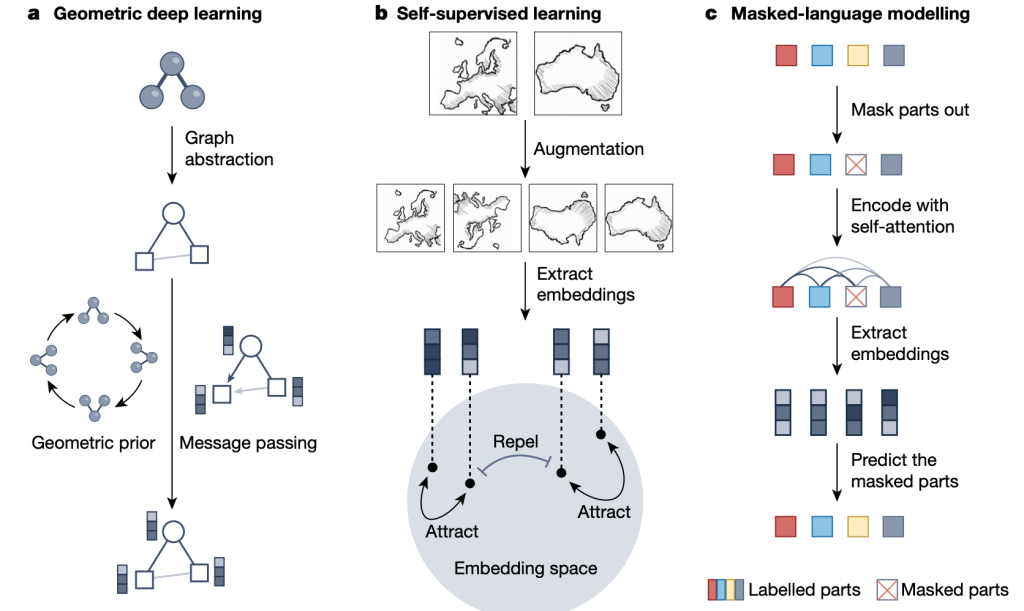
深度学习可以在各种抽象层次上,通常是以端到端的方式,提取科学数据的有意义表征以指导研究。一个高质量的表示应该在保持简单、可及的同时尽可能多地保留数据中信息。科学上有意义的表征是紧凑的(compact)、有判别力的(discriminative),能够解耦潜在的变量并编码可泛化的潜在机制。论文介绍了满足这些要求的三种新兴表征学习策略:几何深度学习、自监督学习和掩码语言建模。
几何深度学习通过利用图(graph)上神经消息传递(neural message-passing)在表征中融入科学数据(如分子和材料)的几何结构和对称性。这种方法首先将研究对象抽象为图结构,随后在图的边(edge)上传递消息得到其潜在表征,同时通过考虑几何先验为模型注入归纳偏置(inductive bias),减少训练所需的数据。
不变性(invariance)和等变性(equivariance)约束是常见的几何先验。例如,分子体系内每个原子所受的合力不随体系的整体平移而变化,但会随着体系的整体旋转而一起旋转。如果我们能让模型满足不变性/等变性约束,即使模型的输出不随/有规律地跟随研究对象的变换而变化,我们就成功向模型注入了几何先验,使其不再需要从数据中学习不变性/等变性的规律,从而更好地理解和操作几何数据。
为得到有效的数据表征,掌握数据点之间的相似和不同至关重要。传统的监督学习方法通过有标签的数据训练模型产生有意义的数据表征,而自监督学习可以利用比有标注数据丰富得多的无标注数据实现这一目标。以对比学习为例,我们首先利用数据增强为每一个数据点产生若干样本(例如经不同角度旋转的卫星图片),在这些增强的数据之间构建正样本对(来自相同数据点的一对样本)和负样本对(来自不同数据点的一对样本)。在学习过程中,我们让模型对齐正样本对的表征、排斥负样本对的表征。经过迭代学习,我们就能得到有意义的、对下游任务表现有所助益的潜在表示。
掩码语言模型(Masked Language Model, MLM)能有效学习序列数据(如自然语言和生物序列)的语义。序列经预处理后被部分掩码,将部分词元(token)替换为特殊的[MASK]词元,然后输入一个 Transformer 块。Transformer 块中的自注意力模型计算每一对词元之间的注意力强度,据此更新其表征并预测被掩码的词元。通过在长序列上反复进行“完形填空”训练,这一模型能生成序列的高质量表征。
用 AI 提出科学假说
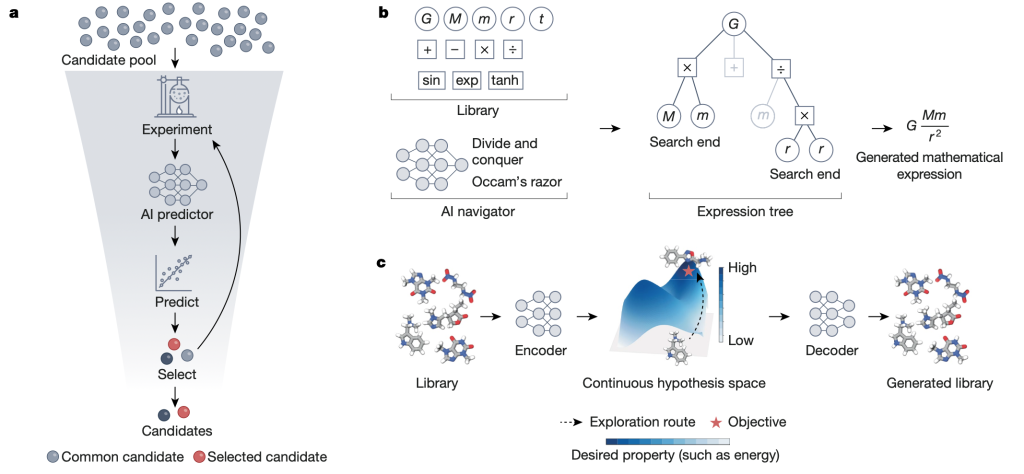
可检验的假设是科学发现的核心,它们可以以数学中的符号表达式(可以检验观测数据是否符合表达式)、化学中的分子(可以检验分子是否具有某种性质)、生物学中的遗传变异(可以检验该变异是否能带来表现型的某种变化)等形式出现。提出这样一种有意义的假设可能需要漫长的时间,例如开普勒花费了四年时间分析恒星和行星数据才得出行星运动规律的假说。AI 可以用以下几种方式帮助人们提出科学假说:
- 黑盒式高通量假说筛选:假说空间过于庞大常常给科学发现带来挑战。以药物发现为例,人类只合成了10^60的潜在药物分子中极小的一部分,它们的理化、生化性质的数据更是残缺不全。通过在已经合成且有实验标注的分子上训练 AI 预测模型,我们就能对庞大的候选分子库进行虚拟(指没有真正进行湿实验)筛选。这种方法不对假设空间的结构做任何预设,它利用一个黑盒式模型对采样到的每一个假说进行筛选。利用前文提到的自监督学习的方法,我们可以将模型在大量已知但未标注的分子上进行表征学习,进一步提高模型的性能。结合湿实验评估和不确定性量化的方法,我们可以将这种高通量筛选流水线化,从而大大提高分子发现的效率、降低成本。
- 在组合式(combinatorial)假设空间中搜索:用采样的方法探索整个假设空间是非常困难的。相比之下,一个更可行的目标是搜索得到一个较优解。在离散的假设空间中,这可以转化为一个组合优化问题。以符号回归为例,符号回归旨在搜索表达空间中最适合(准确+简洁)给定数据集的数学模型。我们可以使用强化学习训练一个智能体,评估搜索树上每个动作(action)的回报,从而让我们能够有效搜索整个假设空间,得到合适的符号表达式。
- 在可微假设空间中优化:在可微空间中,我们可以使用基于梯度(gradient)的最优化方法高效地找到局部最优解。然而,科学假设往往是离散的,这时我们可以用两种方法将其转化到可微空间。一是使用变分自编码器(VAE)这样的模型将离散对象映射到可微的潜在空间(latent space)中,在这个空间内使用优化算法(如图中红星所示),再通过解码器将潜在空间中一点映射回数据空间(data space)。二是直接对数据空间进行松弛(relaxation),随后进行优化。
以上 AI 方法为科学假说的生成、评价和选择提供了强有力的新工具。
用 AI 驱动实验和仿真
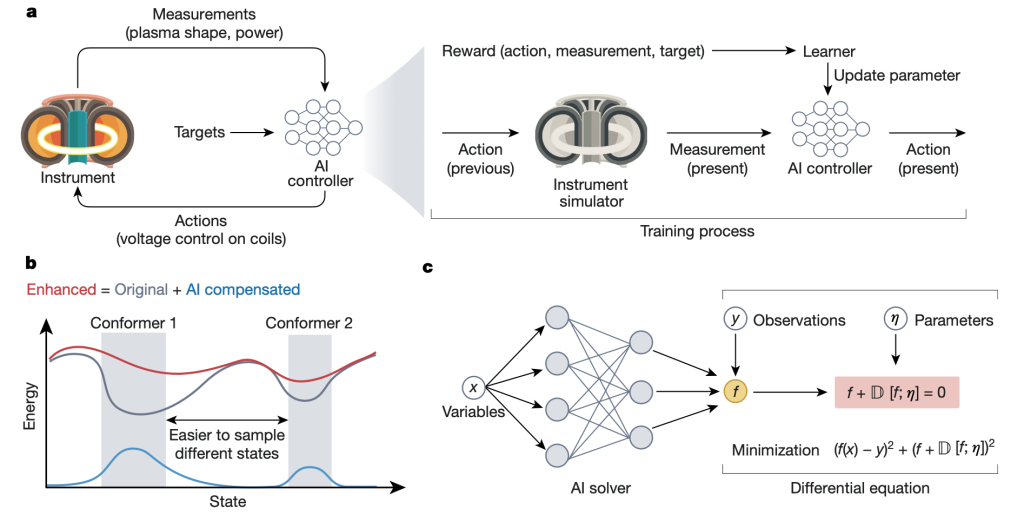
通过实验评估科学假设对于科学发现至关重要。由于湿实验成本高昂,计算机仿真已经成为科学家们感兴趣的替代方案。然而,仿真需要专家基于对科学原理的了解设定参数和策略(heuristics),而且常常难以兼顾效率和速度,精确的仿真往往耗时过长。随着深度学习的普及,这些问题正在被解决。
在实验策划中,AI 系统可以优化实验的参数设置、流程设计等,减少不必要的试验,提高资源利用效率。例如,在材料发现中,主动学习(active learning)的方法使科学家得以在最小的实验次数内降低参数的不确定性。在实验进行时,强化学习模型可以实时调整决策,最大化实验的安全性和成功率。在仿真实验中,AI 系统能够更精确、高效地拟合复杂系统的参数,求解微分方程,建模复杂系统的状态分布以提供定量描述。
结语
正如文中所说,人工智能已然重塑了新时代的科学研究范式,其正在被深度整合到假说生成、实验设计、数据收集、数据分析等科学发现的各个环节。以 ChatGPT 为代表的大语言模型风靡全球,更是向世人展示了 AI 在理解和生成人类自然语言上的惊人能力,同时,也将对药物发现过程产生深刻变革。
百奥几何 CEO 唐建博士认为,科技创新的下一个浪潮将源于 AI 与生命科学的深度对话。蛋白质是重要的生命语言,通过学习十亿级蛋白质序列数据和十万级蛋白质结构数据,理解蛋白质序列、结构与其功能之间的关系,我们就可能从头设计全新的蛋白,重塑蛋白药物发现过程。
正如 DeepMind 创始人、首席执行官德米斯 · 哈萨比斯所说,“这些算法今天已经足够成熟强大,足以被应用于真正具有挑战性的科学问题上了” 。我们坚信,人工智能将会彻底改变药物发现科学家的工作方式,作为 AI for Drug Discovery 的领跑者,百奥几何正在帮助科学家理解生命语言,并为药物发现开辟全新的路径。